Lecture 6: Linear Regression
In Lecture 4, we looked at predicting an MLB player’s 2015 batting average using their 2014 batting average. We did so by binning the data and looking at the average within each bin. What if we wanted to make the bins infinitesimally small? This brings us to the ideas of correlation and the regression method.
We again load the data (if you don’t have it, you can download it here) and use the
pivot_wider function to separate the 2014 and 2015 batting
averages into separate columns.
load("data/batting_2014_2015.RData")
batting_2014_2015 <- batting_2014_2015 %>%
pivot_wider(
names_from = yearID,
values_from = BA,
names_prefix = "BA_"
)
head(batting_2014_2015)## # A tibble: 6 × 3
## playerID BA_2014 BA_2015
## <chr> <dbl> <dbl>
## 1 abreujo02 0.317 0.290
## 2 altuvjo01 0.341 0.313
## 3 andruel01 0.263 0.258
## 4 aybarer01 0.278 0.270
## 5 bautijo02 0.286 0.250
## 6 beltrad01 0.324 0.287Again we plot the 2014 batting averages against the 2015 batting averages:
g <- ggplot(data = batting_2014_2015) +
geom_point(aes(x = BA_2014, y = BA_2015)) +
labs(x = "2014 Batting Average", y = "2015 Batting Average")
g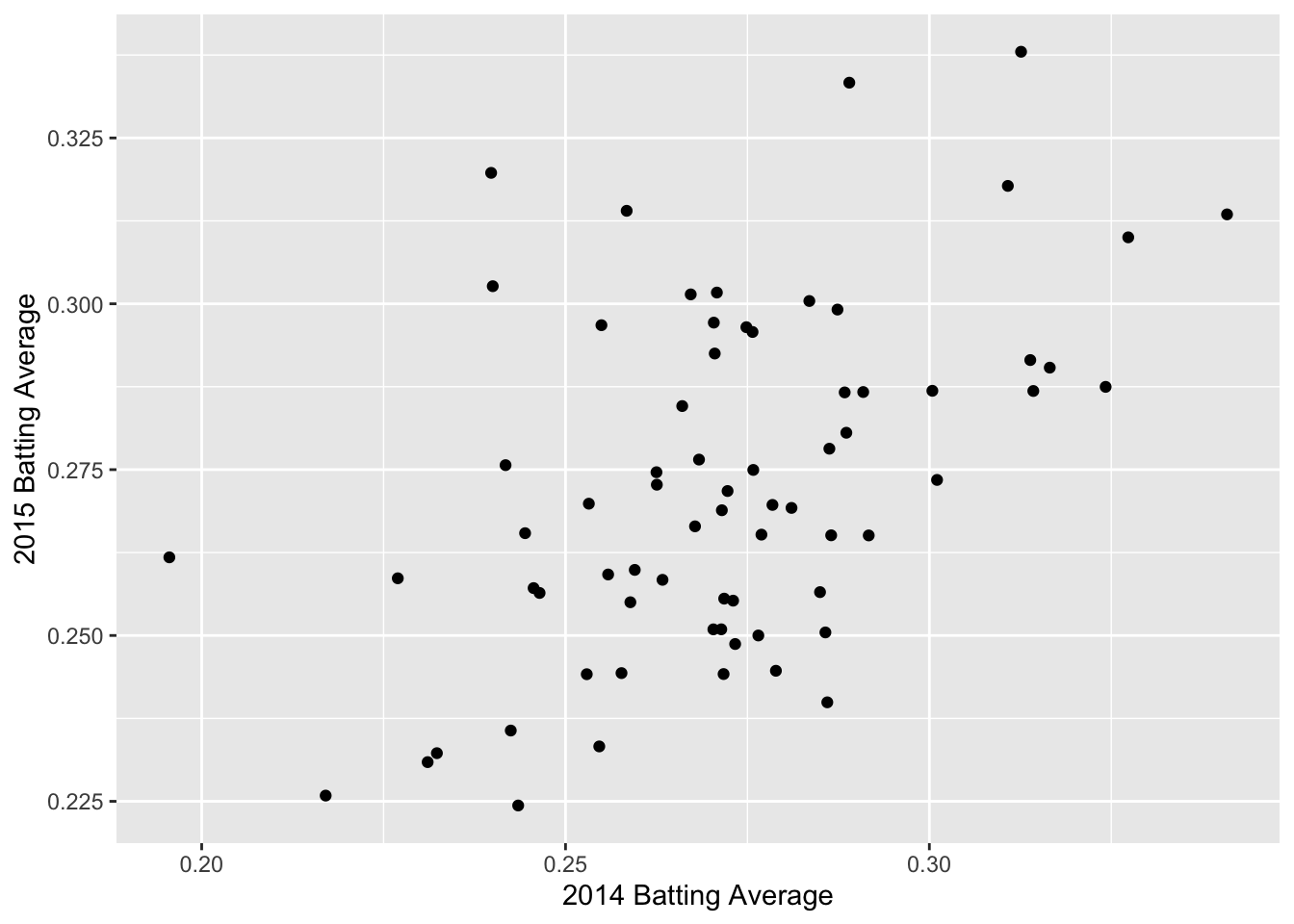
Correlation
We can see a positive trend between the 2014 and 2015 batting averages. How can we quantify the relationship between the 2014 and 2015 data?
The correlation coefficient, r, is one way to summarize the dependence between two seasons with one number. r is a standardized measure of the linear dependence between two variables (usually called \(x\) and \(y\)) and can take values between -1 and +1.
If \(r = 1\), then the points all lie on a line with positive slope. If \(r = -1\), the points all lie on a line with negative slope.
Loosely speaking, we can think of correlation as a measure of how well a line fits our data. Let’s get some practice!
We can calculate the correlation between two variables in
R using the function cor(). Note that
cor() is a Base R function and does not work with the other
tidyverse functions, so we cannot pipe our data into it. Instead, we
need to specifically point to each variable within the dataset, using
the dollar sign symbol we’ve seen a couple times before:
our_dataset$our_variable. This is equivalent to the
tidyverse notation for doing
our_dataset %>% select(our_variable).
The correlation between the 2014 and 2015 batting averages is:
## [1] 0.4928799We have a moderate amount of correlation between 2014 and 2015 batting averages, but there is still a lot of noise.
It is important to remember that correlation is only a measure of linear dependence between two variables. The below example shows data where \(y = x^2\) exactly.
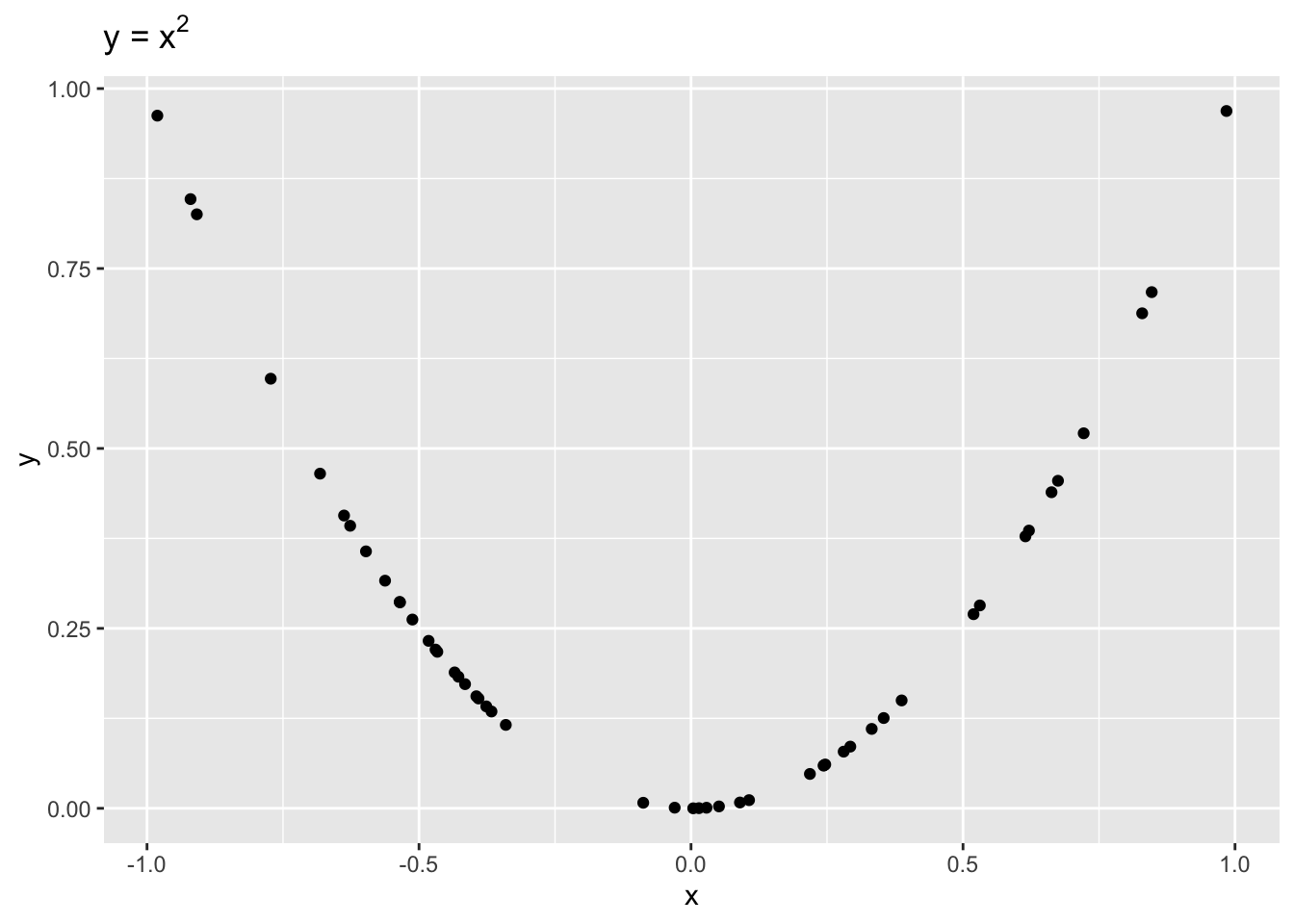
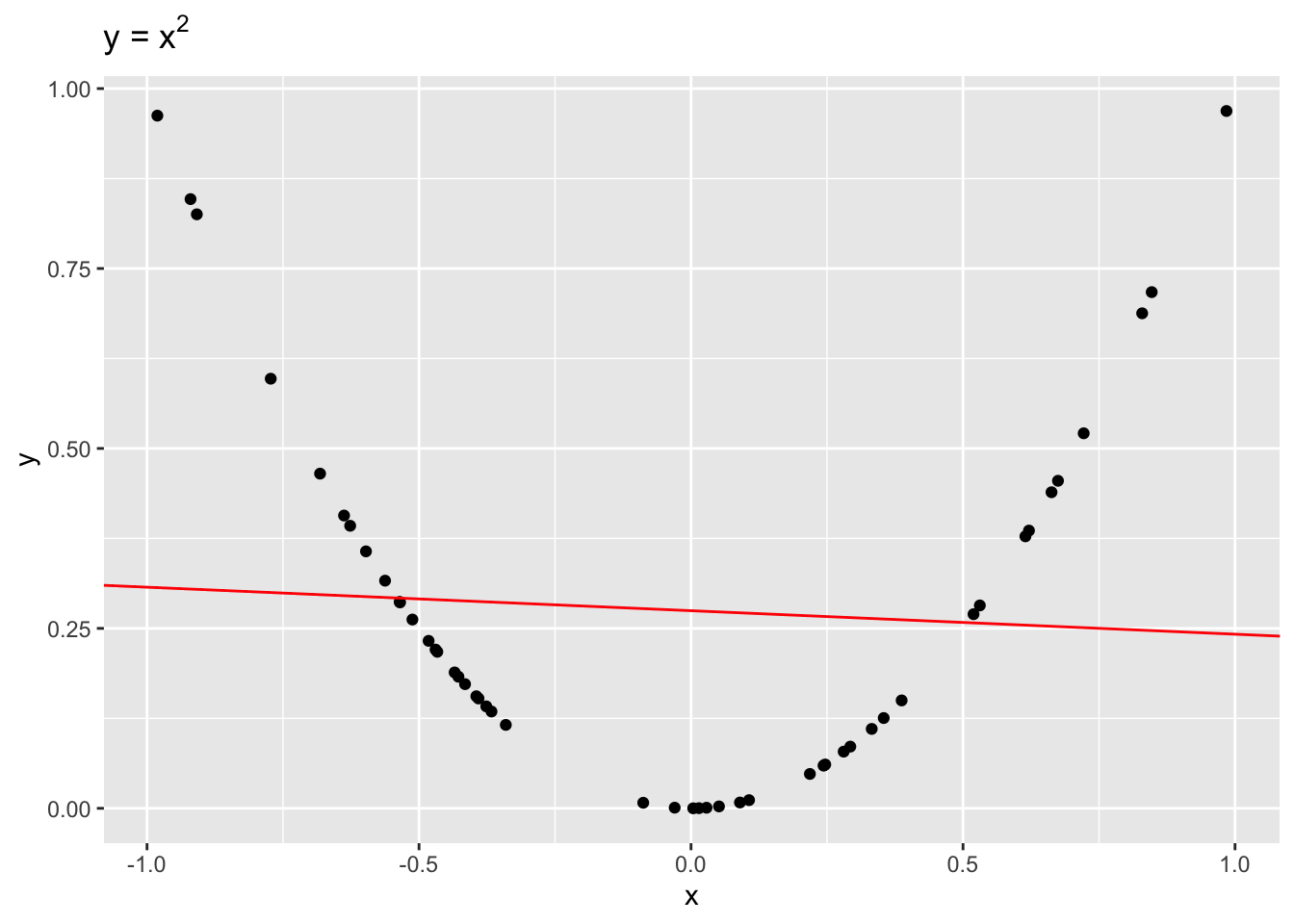
Even though \(x\) and \(y\) are dependent, \(r = -0.1\), indicating a weak linear dependence. If we were to draw a line to fit this data, it would be quite flat!
Now let’s go back to the 2014 and 2015 batting data. To visualize our correlation, we draw the line of best fit through our data. In this example, the line of best fit has \(y\)-intercept = 0.141 and slope = 0.485 (we’ll talk about how we find this values later).
g <- g + geom_abline(intercept = 0.141, slope = 0.485, color = "red") +
labs(title = "y = 0.141 + 0.485x")
g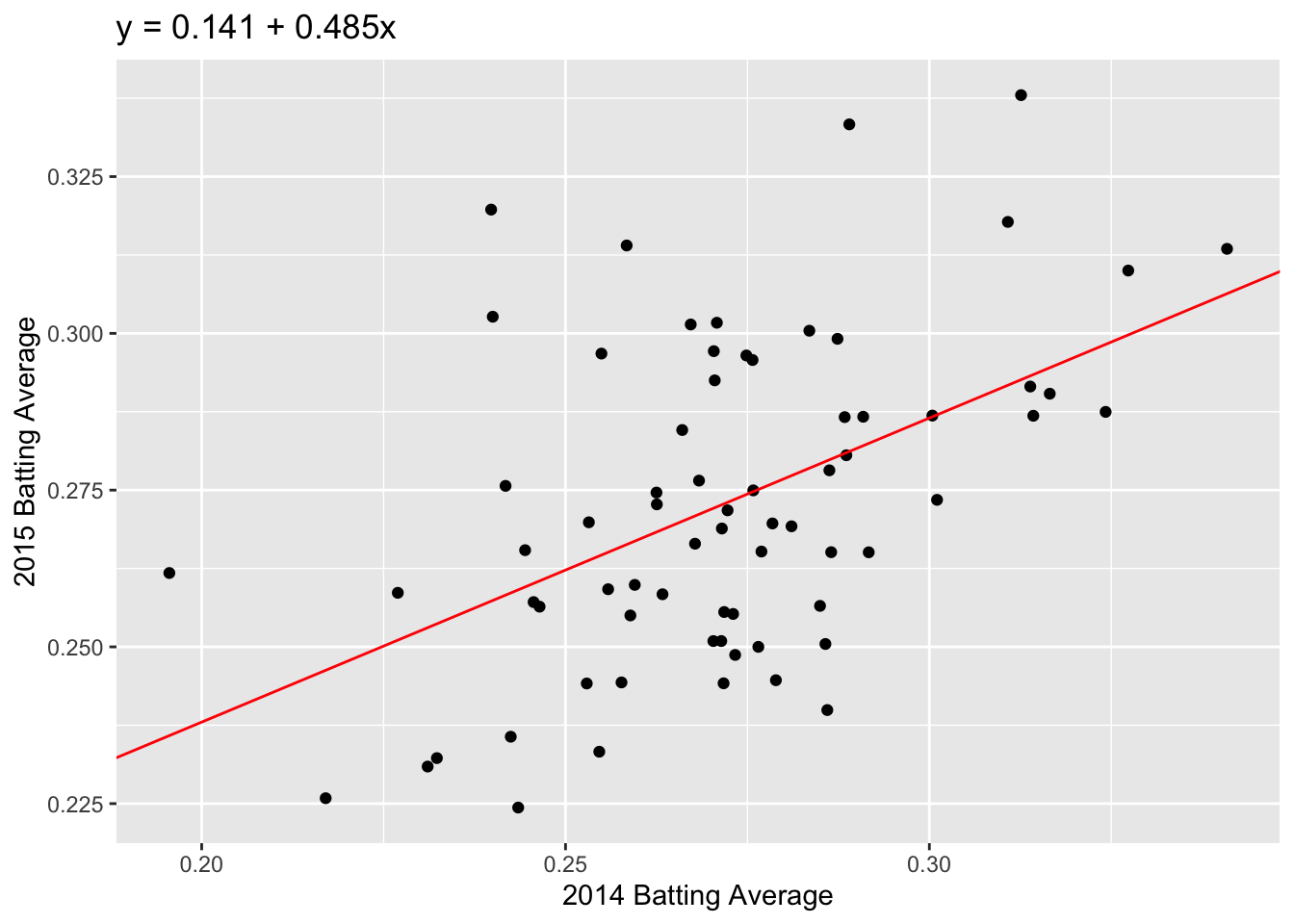
Question: Which feature of the best fit line, \(a\) or \(b\), quantifies the linear dependence between 2014 and 2015 FG%?
How does correlation relate to our line of best fit? This brings us to the regression method.
The Regression Method
If we standardize both datasets, \(x\) and \(y\), the correlation is the slope of the line of best fit:
\[\frac{y - \bar{y}}{sd(y)} = r \times \frac{x - \bar{x}}{sd(x)}\]
We can unpack this equation to get the formula for our unstandardized line of best fit:
\[y = a + bx\] where \(a = \bar{y} - b\bar{x}\) and \(b = r \times sd(y)/sd(x)\).
Now that we have our regression line, we can predict a future \(y\) value given we know \(x\). For example, if we know that a player’s 2014 batting average was 0.31, we predict that their 2015 batting average will be: \[\widehat{y} = 0.141 + 0.485 \times 0.31 = 0.291.\] Note that we use \(\widehat{y}\) for a predicted value of \(y\); we can think of this as \(\widehat{y} = E[Y|x]\).
## Warning in geom_segment(aes(x = 0.19, y = 0.291, yend = 0.291, xend = 0.31), : All aesthetics have length 1, but the data has 70 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.## Warning in geom_segment(aes(x = 0.31, y = 0.2, yend = 0.291, xend = 0.31), : All aesthetics have length 1, but the data has 70 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.## Warning in geom_point(aes(x = 0.31, y = 0.291), color = "dodgerblue", size = 2): All aesthetics have length 1, but the data has 70 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.
Question: What is the interpretation of the slope coefficient, \(b\)?
Fitting linear models
To find the regression coefficients, \(a\) and \(b\), we use the function lm().
The usage of lm() is as follows:
The first argument in the lm() call is called a
formula. This takes input y ~ x, where
y is our response and x is our predictor or
covariate. In the lm() call above, the column
BA_2015 is our response and BA_2014 is our
predictor.
The second argument in lm() is where we specifiy our
data: batting_2014_2015. R then looks for the
columns BA_2014 and BA_2015 in the given
dataset to calculate the regression coefficients.
Our new object, fit, contains a lot of information about
our regression line. At the moment, we just want the coefficients. We
can access the coefficients as follows:
## (Intercept) BA_2014
## 0.1409779 0.4851417We can plot the data by feeding these coefficients to
geom_abline(), however this approach only works for linear
regression. A more efficient way is to use predict() to add
predicted values from the model to our dataset, then add these points to
our plot with geom_line(). We can do this as below:
batting_2014_2015 <- batting_2014_2015 %>%
mutate(pred = predict(model))
ggplot(data = batting_2014_2015) +
geom_point(aes(x = BA_2014, y = BA_2015)) +
geom_line(aes(x = BA_2014, y = pred), color = "lightcoral", size = 1) +
labs(x = "2014 Batting Average", y = "2015 Batting Average") +
labs(title = "Batting Average w/ Regression Line")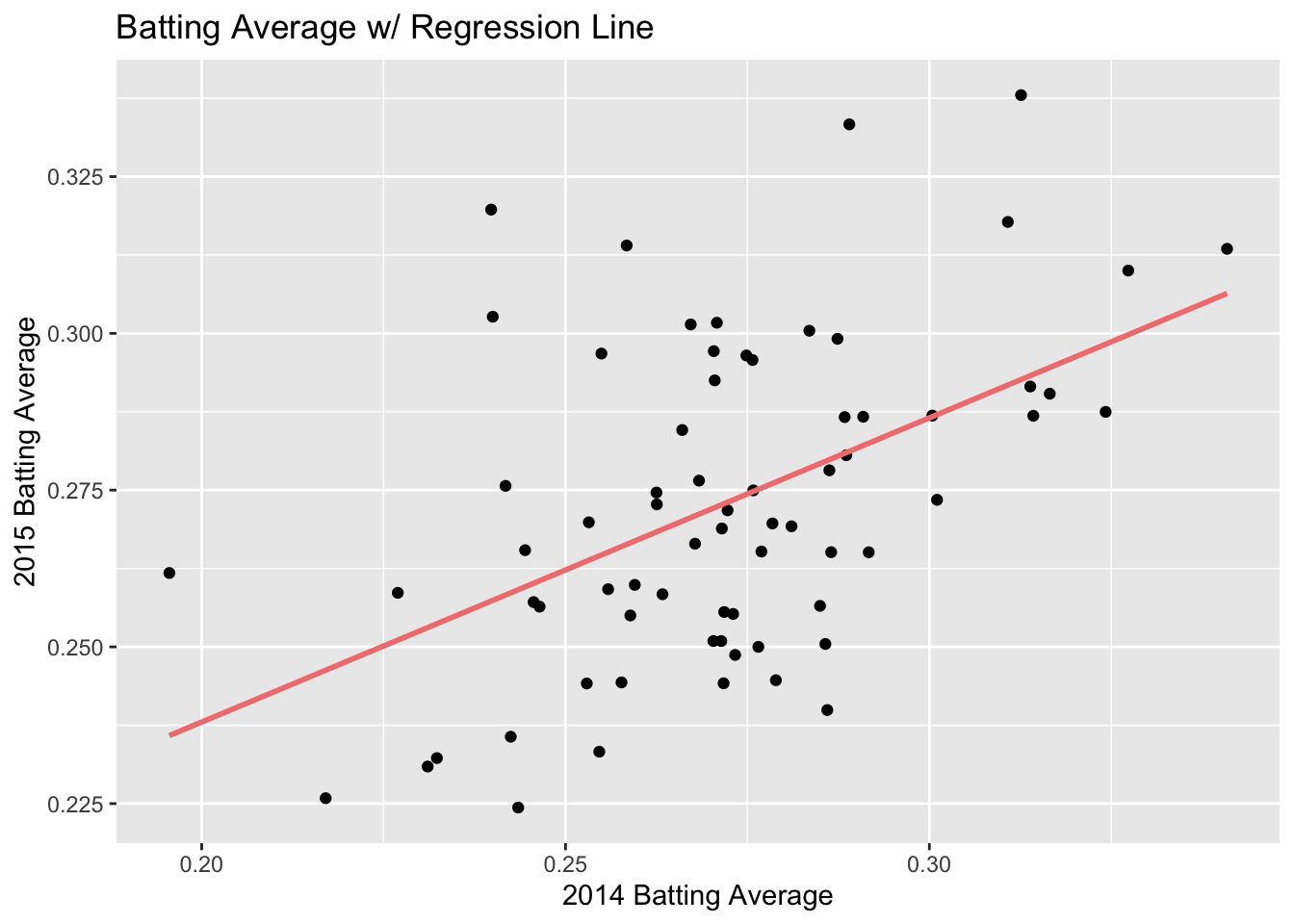
The modelr package
modelr is another package that is part of the
tidyverse. It has a number of useful functions for linear
regression models.
We can use the function rsquare to get the square of the
correlation, \(r^2\). The quantity
\(r^2\) is the proportion of
variance explained by the linear model. The first argument of the
rsquare function is the output fit from our
linear model function lm. The second argument is our
original dataset, batting_2014_2015:
## [1] 0.2429305Adding Predictions and Residuals
We can also use modelr to add predictions and residuals
to our original dataset:
batting_2014_2015 <- batting_2014_2015 %>%
add_predictions(model = fit, type = "response", var = "pred") %>%
add_residuals(model = fit, var = "resid")
batting_2014_2015## # A tibble: 70 × 5
## playerID BA_2014 BA_2015 pred resid
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 abreujo02 0.317 0.290 0.295 -0.00417
## 2 altuvjo01 0.341 0.313 0.306 0.00711
## 3 andruel01 0.263 0.258 0.269 -0.0103
## 4 aybarer01 0.278 0.270 0.276 -0.00638
## 5 bautijo02 0.286 0.250 0.280 -0.0291
## 6 beltrad01 0.324 0.287 0.298 -0.0108
## 7 blackch02 0.288 0.287 0.281 0.00577
## 8 bogaexa01 0.240 0.320 0.257 0.0624
## 9 brantmi02 0.327 0.310 0.300 0.0102
## 10 braunry02 0.266 0.285 0.270 0.0145
## # ℹ 60 more rowsIn add_predictions, we have to specify three arguments:
(i) the model, which is just the output of lm(), (ii) the
type, which will always be “response” for this course, and (iii) the
name of the column we want our predictions to be stored in. We similarly
have to specify a model and var argument in
add_residual.
Using these new columns, we can create the original plot and add the residual lengths:
g <- ggplot(batting_2014_2015) +
geom_segment(aes(x = BA_2014, xend = BA_2014, y = BA_2015, yend = pred), color = "dodgerblue") +
geom_point(aes(x = BA_2014, y = BA_2015)) +
geom_abline(intercept = 0.1409779, slope = 0.4851417, color = "red")
g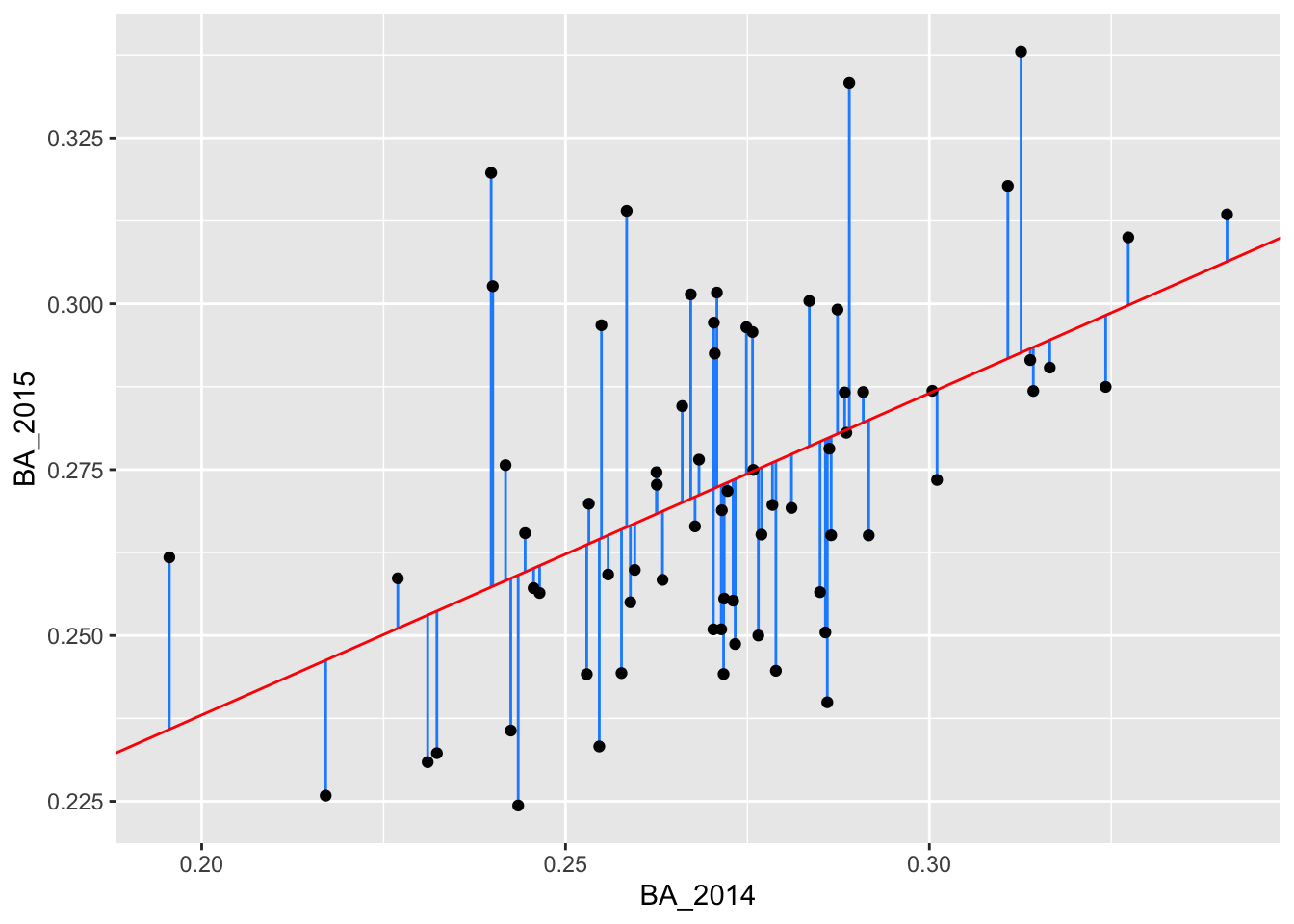
Predict
So far we have looked at the predicted values from our
training data; that is, the data we used to fit our linear
model. Suppose we have more players’ batting averages from 2014 but we
do not have their batting averages from 2015. We can once again use the
predict function to obtain values for these new players
based on our model.
In the below code, we enter the players’ 2014 batting averages as the
tibble new_data. We then use the function
predict. The first argument of predict is the
fitted model, model. The second argument is
new_data.
## 1 2 3
## 0.2578971 0.2913719 0.2695405We can also add these predictions to new_data using
add_predictions:
## # A tibble: 3 × 2
## BA_2014 pred
## <dbl> <dbl>
## 1 0.241 0.258
## 2 0.31 0.291
## 3 0.265 0.270We add these predictions to our plot:
ggplot(batting_2014_2015) +
geom_point(aes(x = BA_2014, y = BA_2015)) +
geom_line(aes(x = BA_2014, y = pred), color = "lightcoral", size = 1) +
geom_point(data = new_data, mapping = aes(x = BA_2014, y = pred), color = "dodgerblue")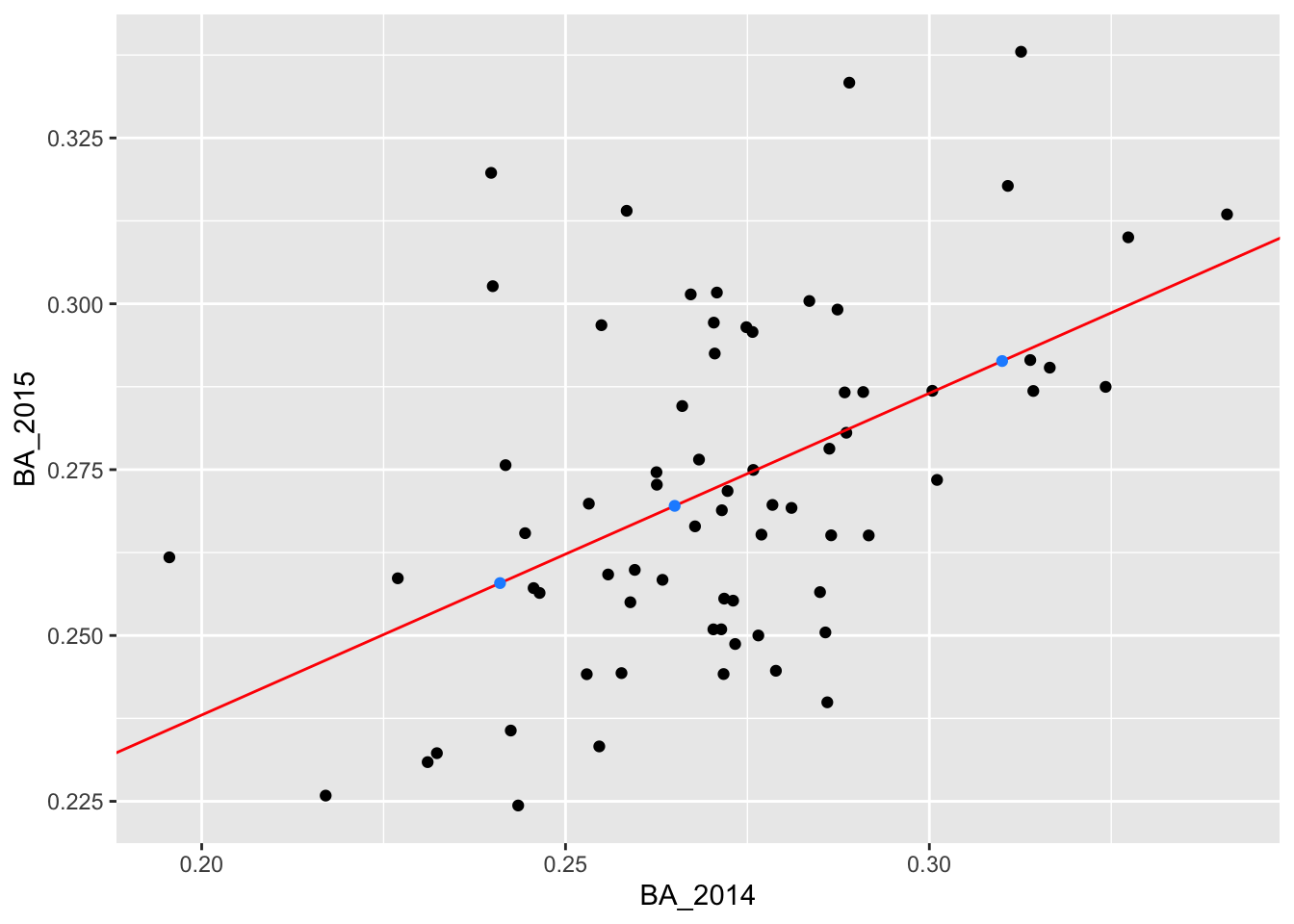
For more details on modelling using the tidyverse, you
can look at Chapter
23 of the book R for Data Science by Hadley Wickham and
Garrett Grolemund. It’s also a great reference in general!